
提到MYSQL的优化,绕不开的一点那就是索引。
但是当我第一次看到“索引优化”这个词,其实十分的茫然。
我记得最初的印象就是,加上了索引以后,查询速度会变快。
但究竟“索引”是个什么东西?
MySql官方给出的定义为:帮助MySql高效获取数据的数据结构。
得到了关键词——数据结构。
这也就明了了,索引的底层,不是其他东西,恰恰就是某一种特定的数据结构。
那么,是什么数据结构呢?
索引的目的其实是为了将所有的数据排好序,以此提升数据库的查找效率,那么显而易见,我们需要一个在查找方面性能较好的数据结构。
传统的红黑树和二叉树行不行?
来看一看他们的查找效率就知道了。
假设我们有一串连续数据1、2、3、4、5、6、7、8。
用二叉树来存储,得到的结构会是如下的:
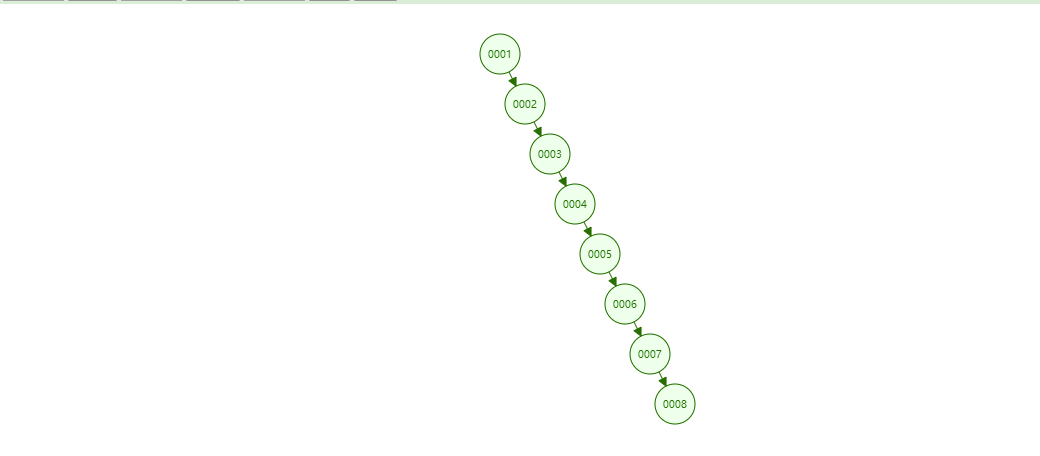
如果说我要查8号元素,得要连续查询8次。
那如果用红黑树呢?
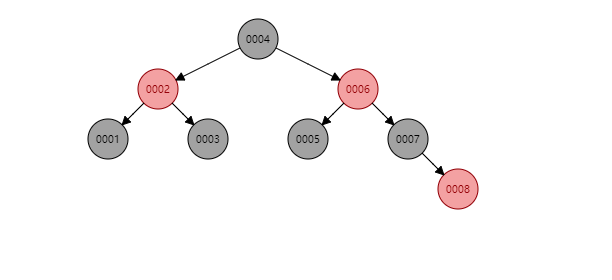
只需要4次。
两者对比,红黑树优势明显。
但是MySql底层会使用红黑树吗?
显然不会。
我们这里举的例子仅仅是只存了8条数据,但是现实场景中的业务量是远远大于8条数据的。
仅仅8条数据就要查询那么多次,现实中百万的数据量,并不能显著减少数据库的查询次数。
那么,有没有一种结构,无论数据的多少,查询的次数都可以维持在一个相对较少的水平呢?
那么就要对现有的数据结构进行优化。
我们可以看到,不论红黑树还是二叉树,查询的次数由树的层数所决定。
那如果要达成刚才所说的目标,就必须要减少树的层数,这样才可以减少查询的次数。
此前我们只是在每个节点上存储了一个数据,如果说我们能在每个节点上存储多条数据,那么树的层数也会大大减少。
这种数据结构也就是MySql用的BTree结构。
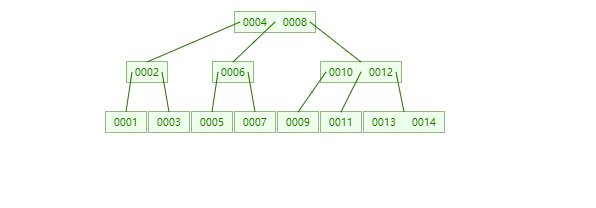
可以看见,节点上不再只有一条数据,随着数据的不断增多,Btree会不断变换,将树的层数维持在一定范围内。
如果说是三层的树,那么无论查什么数据,只要查三次就必然可以命中。
传统的BTREE是将数据和索引同时存在节点上。
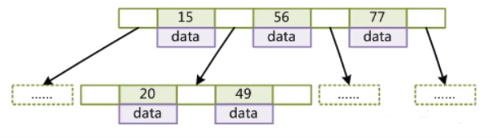
如同这样,通过传统二叉树的思想,将多条数据存在同一个节点上,用15举例,如果查询小于15的数据,则通过15左侧的指针去下一层查找,如果查询大于15的数据,则通过右侧指针去下一层查找。
MYSql把传统BTree进行了优化。
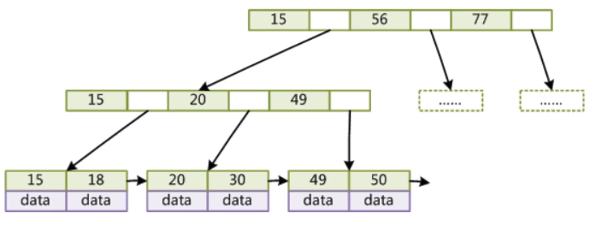
在非叶子节点不再存储数据,转而把数据统一存储到叶子节点上,相当于增加了一个冗余的索引字段。
这也就是所谓的B+Tree。
那我们看看这样做有什么好处。
从图中可以很明显了解到,每个索引数据的构成从原来的数据,索引标记和指向下一层的指针变为了只有索引和指针。
那么对应的非叶子节点的数据的存储空间也就被节省下来了。
也就意味着,一个节点中可以存储更多的索引数据。
那么每个索引数据的大小是多少?
指针的大小大约为6B,索引的标记大小大约为8B。
MySql默认的节点大小为16KB。
我们可以计算出,一个节点可以存储的索引标记数量约为1170个。
我们再分析一下叶子节点的数据,根据不同的存储引擎,可能在叶子节点会存储数据或者指针。
我们假设每个叶子节点索引数据为1KB,那么每个叶子节点可以存16条数据。
假设我们是一个三层的B+Tree,那么可以存储的数据量就是1170117016=21902400
也就是超过了两千万条数据。
最关键的一点是,两千万条数据无论哪一条都只需要查询三次便可定位到。
比起漫无目的的全表遍历,效率自然提升了很多。
这也就是单一索引的构成。
但是正式环境下,如果对数据表检索,很可能并不只有一个条件。
因此,诞生了组合索引,即一个索引包含多个列。
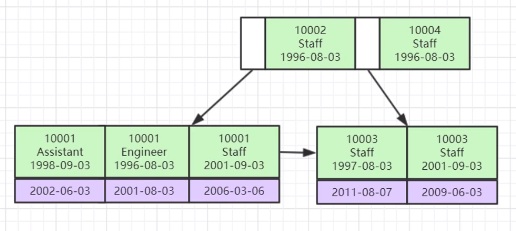
常见的组合索引存储方式如图所示,其结构同样基于BTree,和单一索引不同的是,组合索引在第一个字段按照BTree排列后,再通过第二个字段继续排列,以此类推。
这就是MySql索引的结构,下篇介绍索引失效的情况。
